با گسترش بازار کار برای دانشمندان داده ( data scientists ) در این روزها ، بسیاری از افراد واقعاً برای کسب لیست های شغلی دانشمند داده به دنبال مجموعه های مختلف مهارت های فنی هستند. برای کلیه پست های شغلی مرتبط با علم داده در Indeed.com در سال ۲۰۱۹ ، ۴۶۴ مهارت مختلف ذکر شده است.

بدیهی است که راهی برای تسلط بر همه این مهارتها وجود ندارد ، بنابراین مهم است که بدانیم مجموعه خاصی از مهارتهای فنی برای نوع کار دانشمند داده مورد نظر مورد نیاز است.
در واقع برای حل این مشکل از رویکرد علم داده، ما مدل سازی موضوع LDA را در مورد مهارتهای فنی ذکر شده در هر لیست شغلی مرتبط با علم داده انجام دادیم تا بدانیم که کدام مجموعه از مهارتهای فنی به احتمال زیاد در یک لیست شغلی هم ذکر شده است. مجموعه داده ما از این نوع داده در Kaggle آمده است.
# Data Preprocessing on the skill column
df=pd.read_csv('indeed_job_dataset.csv')
text_data=[]
for skills in df.Skill.dropna():
lst=skills[1:-1].split(', ')
words=[]
for item in lst:
words.append(item[1:-1])
text_data.append(words)# Topic Modelling
from gensim import corpora
dictionary = corpora.Dictionary(text_data)
corpus = [dictionary.doc2bow(text) for text in text_data]
import pickle
pickle.dump(corpus, open(‘corpus.pkl’, ‘wb’))
dictionary.save(‘dictionary.gensim’)# Setting the total number of topics to be 3 here
NUM_TOPICS = 3
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = NUM_TOPICS, id2word=dictionary, passes=15)
ldamodel.save(‘model5.gensim’)
topics = ldamodel.print_topics(num_words=4)نتیجه مدلسازی موضوع ما را تجسم می کند
dictionary = gensim.corpora.Dictionary.load(‘dictionary.gensim’)
corpus = pickle.load(open(‘corpus.pkl’, ‘rb’))
lda = gensim.models.ldamodel.LdaModel.load(‘model5.gensim’)
import pyLDAvis.gensim
lda_display = pyLDAvis.gensim.prepare(lda, corpus, dictionary, sort_topics=False)
pyLDAvis.display(lda_display)
می توانیم ببینیم که وقتی تعداد مباحث خود را به سه مورد تنظیم می کنیم ، اولین نوع کار نقش سنتی دانشمند داده است ، جایی که کارفرما به دنبال مهارت های R ، Python ، SQL و یادگیری ماشین(Machine Learning) است.
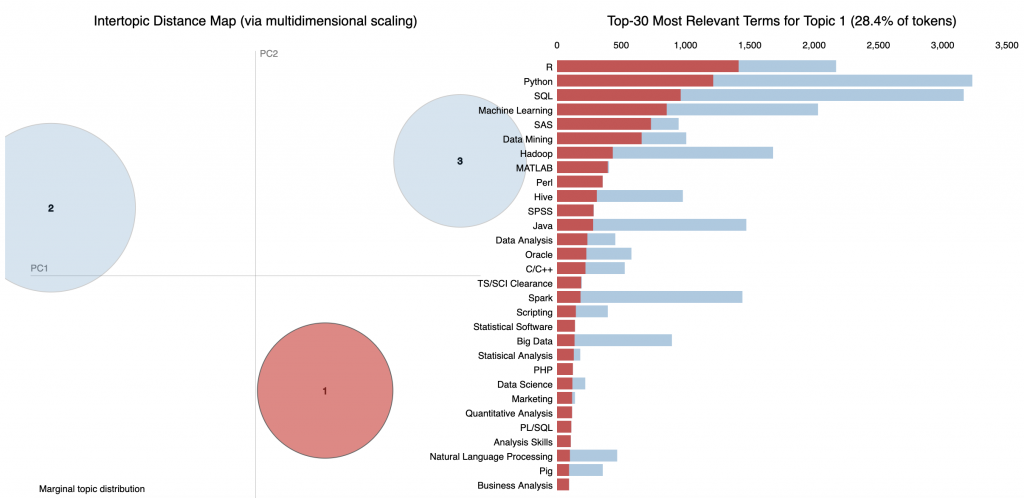
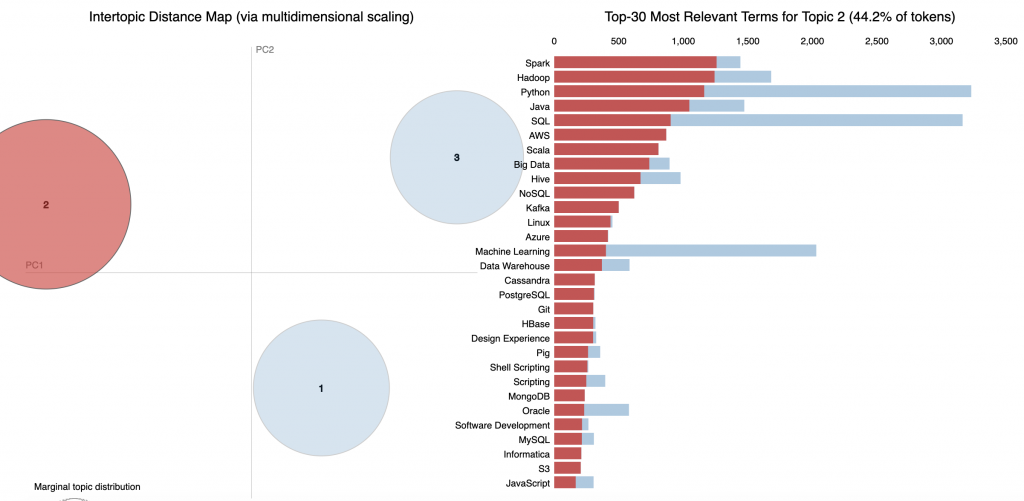
در همین حال ، مهارت های مورد نیاز برای نوع شغل شماره ۲ در اینجا کمی متفاوت است – Spark ، Hadoop ، AWS ، Scala – این بدیهی است که نقش دانشمند داده بیشتر داده های بزرگ(big data) و متمرکز بر فضای ابری (cloud-focused ) است.
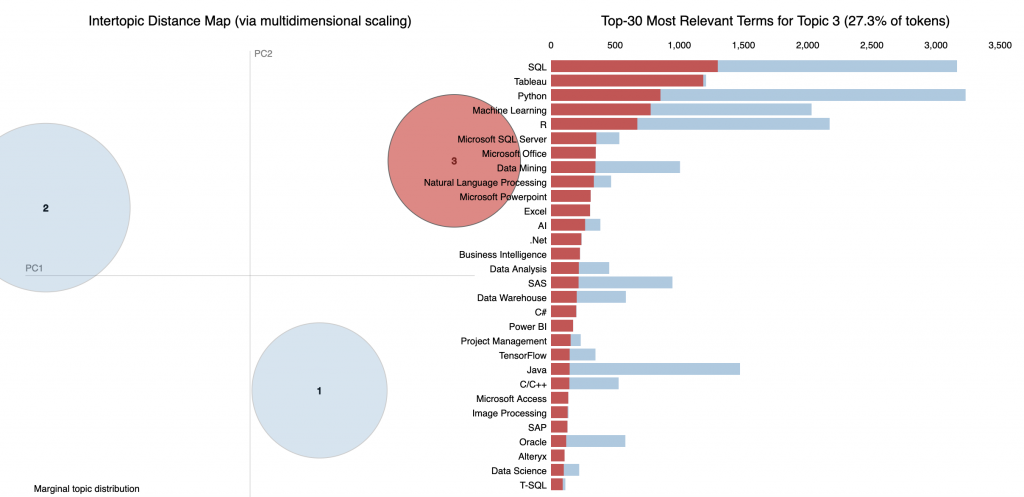
و در آخر اینکه ، برای نوع شغل سوم ، این به وضوح یک نقش تحلیلگر داده است ، با تمرکز بر استفاده از SQL ، Tableau و SQL Server.
بنابراین ، ما برای دستیابی به حقوق بالاتر در واقع به چه تعداد مهارت نیاز داریم؟ هرچی بیشتر بهتر! خب، شاید به جز این شما به نقشهای مدیریتی بیشتری روی آورید ، به همین دلیل است که بالاترین کارنامه حقوق و دستمزد در اینجا شاهد کاهش تعداد مهارت های مورد نیاز است.
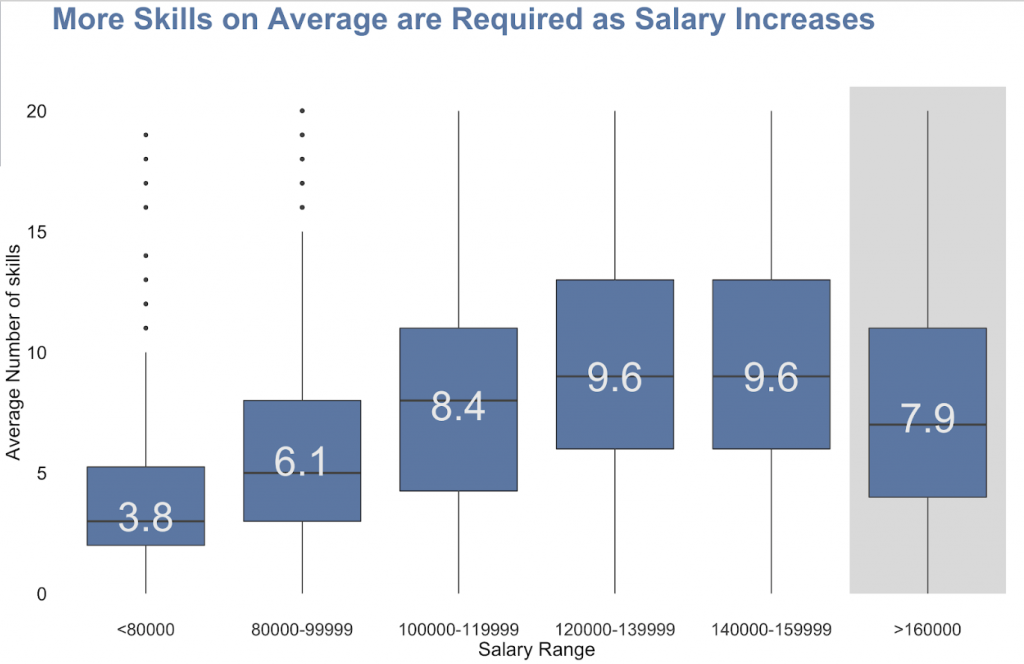
پس از انجام موضوع مدل سازی ، جالب بود بدانید که این روزها چگونه R هنوز در بسیاری از پست های شغلی دانشمند داده بسیار مورد تقاضاست، حتی اگر به نظر می رسد زبان پایتون تسلط بیشتری در صنعت دارد. ما فکر کردیم که ممکن است به این دلیل باشد که بسیاری از لیست ها R و Python را در بخش مهارت ها قرار می دهند ، اما واقعاً به R / Python احتیاج دارند.
با این حال ، ما فکر کردیم که ممکن است انجام مقایسه ای بین R و Python جالب باشد ، بدانیم که دانستن پایتون به جای R باعث افزایش حقوق شما می شود یا نه.
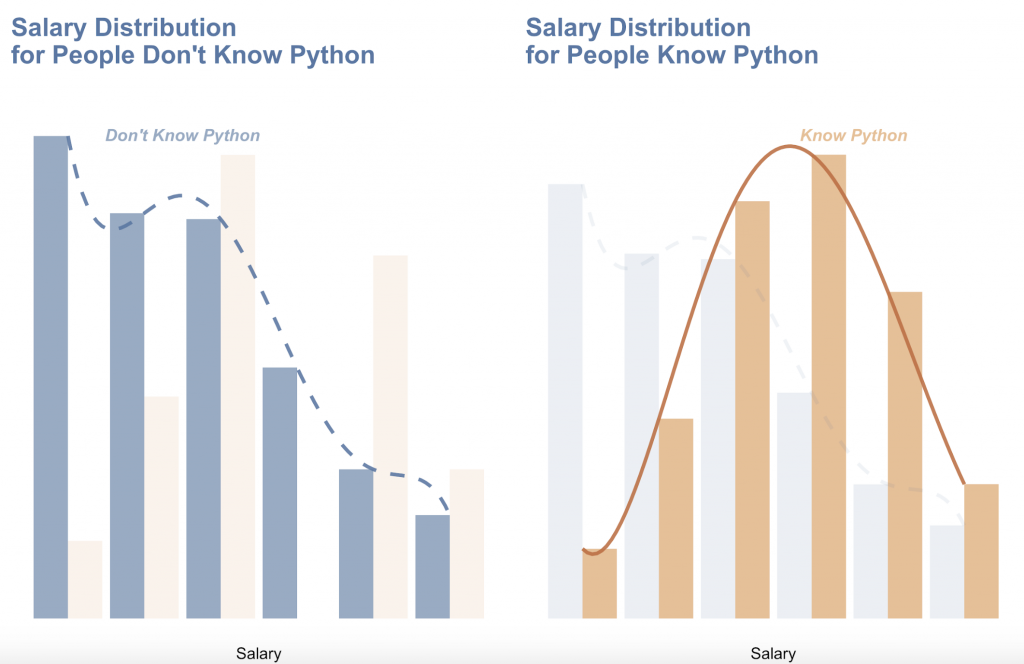
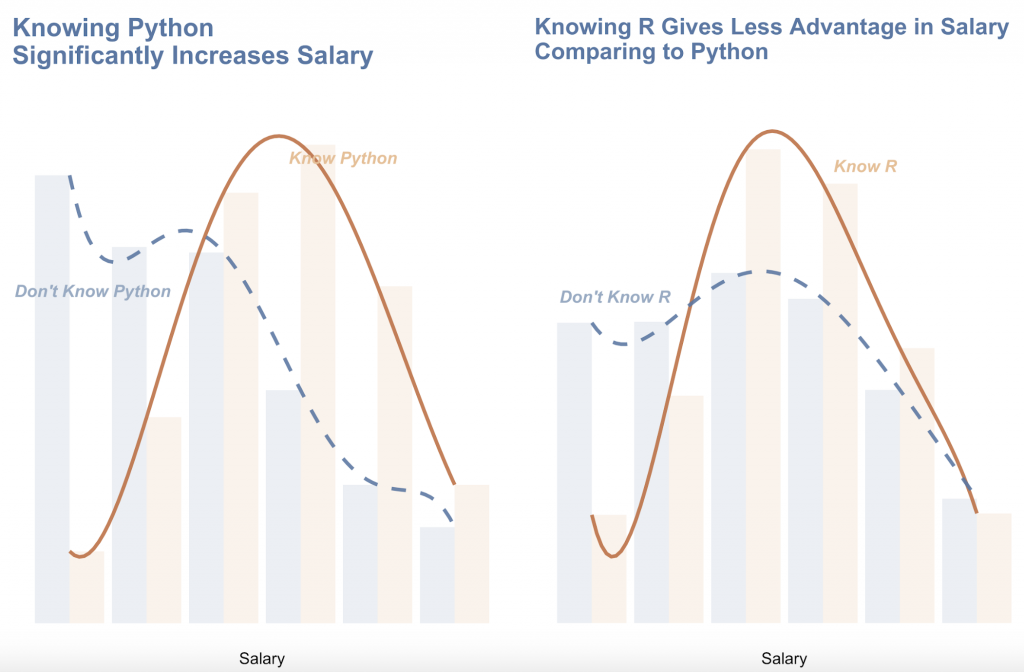
ما می توانیم ببینیم که در مقایسه با دانستن R ، دانستن پایتون در فرود حقوق بالاتر مزیت بیشتری به شما می دهد.
امیدوارم که این امر بتواند روند شکار شغلی شما را در این راه کمی آسانتر انجام دهد ، ممکن است همه رویاهای داده های ما به واقعیت تبدیل شوند.
این یک پروژه گروهی برای MSDS 593 در دانشگاه سانفرانسیسکو بود ، اعضای این گروه استر لیو و زو لیو هستند.
احساس رایگان نموده و از repo GitHub برای پیش پردازش و مصورسازی ما استفاده کنید.
مرجع:
[۱] Li,Susan, Topic Modeling and Latent Dirichlet Allocation (LDA) in Python(2018), https://towardsdatascience.com/topic-modeling-and-latent-dirichlet-allocation-in-python-9bf156893c24